 SIEM
SIEM
В какой-то момент ИБ-департамент крупной компании неизбежно задумывается о внедрении или замене SIEM-системы и сталкивается с задачей оценки бюджета, необходимого для ее внедрения. Но SIEM — это не легковесный продукт, который можно развернуть в имеющейся инфраструктуре. Практически все решения этого класса требуют дополнительного оборудования, так что для их работы придется приобретать аппаратное обеспечение (или арендовать его).
Поэтому для расчетов бюджета необходимо представлять себе предполагаемую конфигурацию оборудования. В этом посте мы попробуем рассказать о том, как архитектура SIEM влияет на требования к аппаратной составляющей, а также предоставим примерные параметры, на которые стоит ориентироваться, чтобы определить предварительную стоимость необходимого оборудования.
Оценка потока информации
По своей сути SIEM-система собирает данные о событиях с источников и на основании корреляции этих данных выявляет угрозы для безопасности. Поэтому, прежде чем прикидывать, какое железо необходимо для работы системы, стоит оценить, а какой, собственно, объем информации эта система будет обрабатывать и хранить. Для того чтобы понять, какие источники потребуются, следует выделить наиболее критичные риски и определить источники данных, анализ которых поможет в выявлении и анализе угроз, связанных с этими рисками. Такая оценка нужна не только для расчета необходимого аппаратного обеспечения, но и для оценки стоимости лицензии. Например, стоимость лицензии на нашу систему KUMA (Kaspersky Unified Monitoring and Analysis Platform) напрямую зависит от количества событий в секунду (Events Per Second, EPS). И еще один важный аспект — при выборе SIEM-системы важно проверить, как именно вендор считает количество событий для лицензирования. Мы, например, учитываем количество EPS после фильтрации и агрегации, причем мы считаем среднее количество событий за последние 24 часа, а не их пиковые значения, но так поступают далеко не все.
К наиболее распространенным источникам относятся конечные точки (события Windows, Sysmon, журналы PowerShell, а также антивирусов), сетевые устройства (брандмауэры, IDS/IPS, коммутаторы, точки доступа), прокси-серверы (такие как Squid, Cisco WSA), сканеры уязвимостей, базы данных, облачные системы (например, AWS CloudTrail или Office 365), серверы управления инфраструктурой (контроллеры домена, серверы DNS и так далее).
Как правило, для того чтобы сформировать предварительные ожидания по среднему потоку событий, можно ориентироваться на размер организации. Но следует помнить, что в силу архитектурных особенностей конкретной информационной инфраструктуры размер компании может быть и не решающим параметром.
В общем же случае для небольшой и средней организации с одним или несколькими офисами, с хорошими каналами связи между ними и ИТ-инфраструктурой в едином ЦОД можно ожидать средний поток событий в 5000–10 000 EPS. Для крупной компании такую оценку дать сложнее, в зависимости от сложности инфраструктуры и наличия филиалов разброс может составлять 50 000–200 000 EPS.
Архитектурные компоненты SIEM-системы
По большому счету SIEM-система состоит из четырех основных компонентов: подсистемы управления, подсистемы сбора событий, подсистемы корреляции и подсистемы хранения.
Ядро (подсистема управления) — своеобразный центр управления. Оно позволяет управлять остальными компонентами и обеспечивает инструмент визуализации для удобства SOC-аналитика, предоставляя ему возможность легко настраивать параметры работы, получать информацию о состоянии SIEM-системы и, самое главное, просматривать, анализировать, сортировать и искать события, обрабатывать алерты, работать с инцидентами. Центр управления также должен обеспечивать возможность просмотра логов с помощью виджетов, панелей мониторинга и предоставлять возможность быстрого поиска и просмотра данных.
Ядро является обязательным компонентом и может быть установлено как в единственном экземпляре, так и в виде отказоустойчивого кластера.
Подсистема сбора событий, как не сложно догадаться по ее названию, служит для сбора данных от разных источников и приведения их к единому формату при помощи парсинга и нормализации. Чтобы рассчитать требуемую мощность этой подсистемы, нужно учитывать не только интенсивность потока событий, но и формат логов, в котором они приходят от источников событий.
Нагрузка на сервер зависит от того, как именно подсистема работает с логами. Например, даже для структурированных логов (Key Value, CSV, JSON, xml) можно использовать регулярные выражения (что требует существенно более производительного железа), а можно использовать встроенные вендором парсеры.
Подсистема корреляции служит для анализа данных, собранных из логов, выявления последовательностей, описанных в логике правил, и, при необходимости, создания алертов, а также определения степени их угрозы и минимизации ложноположительных срабатываний. Следует помнить, что нагрузка на коррелятор определяется не только потоком событий, но и количеством корреляционных правил, а также методами описания детектирующей логики.
Подсистема хранения. SIEM-система должна не только анализировать, но и хранить данные: для проведения внутренних расследований; аналитики и визуализации информации с последующим формированием отчетов; в некоторых отраслях — для выполнения требований регуляторов; а также ретроспективного анализа алертов. Поэтому еще один важный вопрос, который необходимо решить на этапе проектирования SIEM-системы, это как долго вы хотите хранить собранные логи. Вероятно, с точки зрения аналитика, чем дольше данные хранятся, тем лучше, но глубина хранения логов повышает требования к аппаратному обеспечению, поэтому зрелая SIEM-система должна предусматривать возможность соблюдения баланса — назначать разную глубину хранения для разных типов логов. Например, NetFlow — 30 дней, информационные события Windows — 60 дней, события аутентификации Windows — 180 дней и так далее. Это позволяет оптимальным образом компоновать данные в имеющиеся ресурсы сервера.
Также важно понять, какой объем данных будет храниться методом горячего хранения (то есть обеспечивающим возможность оперативного доступа к ним) и какой — методом холодного хранения (подходящим для долгосрочного хранения).
Подсистема хранения должна обладать высокой производительностью, а также иметь возможности масштабирования, сквозного поиска в разных областях хранения (как в «горячем», так и в «холодном» хранилище) и просмотра данных. Также крайне важно, чтобы она могла обеспечивать возможность резервного копирования данных.
Архитектурные особенности KUMA
Разумеется, когда мы пишем, какой должна быть SIEM-система, мы подразумеваем, что наша система — KUMA — такой и является. Благодаря изначально заложенной возможности масштабировать решение для поддержки потока данных в сотни тысяч EPS в рамках одного инстанса, она не боится больших нагрузок. И главное, не нуждается в разделении на несколько инстансов с последующим сведением результатов корреляции (в отличие от ряда аналогов).
Подсистема сбора событий нашей SIEM-системы имеет богатый набор парсеров, оптимизированных под обработку логов каждого из форматов. А многопоточность Go позволяет обрабатывать поток событий всеми имеющимися на сервере ресурсами.
Применяемая в KUMA подсистема хранения данных состоит непосредственно из серверов, хранящих данные, и серверов с ролью ClickHouse Keeper, служащих для управления кластером (то есть сам он ничего не хранит, но помогает инстансам договариваться между собой). При потоке данных в 20 тысяч EPS и при условии не очень большого количества поисковых запросов эти сервисы могут работать на серверах, которые хранят данные. А вот при больших потоках рекомендуется выносить эти сервисы отдельно. Например, на виртуальные машины (потребуется как минимум одна, но рекомендуется использовать три).
Система хранения KUMA SIEM гибкая, она позволяет распределить поток событий по нескольким спейсам и для каждого спейса указать свою глубину хранения. Например, она позволяет поставить недорогие диски и сделать на их базе холодное хранилище (в нем также доступен поиск, но выполняться он будет дольше). В нем можно хранить данные, которые вряд ли потребуются для анализа, но должны храниться по требованию регулятора, — такую информацию можно помещать на холодное хранение буквально на следующий день после появления.
Таким образом, подход к хранению данных, реализованный в нашей SIEM-системе, позволяет хранить данные в течение длительного времени без превышения бюджета на дорогостоящее оборудование — благодаря возможностям горячего и холодного хранения.
Архитектура развертывания SIEM-системы на примере KUMA
SIEM-система KUMA поддерживает несколько вариантов развертывания, поэтому перед внедрением важно определить, какая архитектура SIEM нужна вашему предприятию. Это можно сделать, опираясь на расчетный поток EPS и нюансы конкретной компании. Для простоты будем считать, что требуемая глубина хранения данных у нас составляет 30 суток.
Поток данных 5000–10 000 EPS
Если организация невелика, то SIEM вполне можно развернуть и на единственном сервере. Например, если говорить о нашей SIEM-системе, то она поддерживает вариант установки Kaspersky SIEM All-in-One. В таком случае требуется сервер с конфигурацией 16 CPU, 32 ГБ RAM, емкость хранилища — 2,5 ТБ.
Поток данных 30 000 EPS
Для более крупных организаций потребуется установка сервера под каждый из компонентов SIEM. Следует выделить отдельный сервер хранения, чтобы поисковые запросы не влияли на обработку событий коллектором и коррелятором. Но сами сервисы коллекторов и коррелятора по-прежнему можно разместить вместе (впрочем, можно и разделить). Примерная конфигурация необходимого оборудования такова:
- Ядро — (10 CPU, 24 ГБ RAM, емкость хранилища 0,5 ТБ).
- Коллектор — (8 CPU, 16 ГБ RAM, емкость хранилища 0,5 ТБ).
- Коррелятор — (8 CPU, 32 ГБ RAM, емкость хранилища 0,5 ТБ).
- Хранилище — (24 CPU, 64 ГБ RAM, емкость хранилища 14 ТБ).
Поток данных от 50 000 до 200 000 EPS
Если мы рассматриваем крупные компании, то у нас появляются дополнительные параметры, которые нужно учитывать при определении архитектуры. Во-первых, это обеспечение отказоустойчивости (так как поток данных становится существенным и это повышает риск сбоя), а также наличие подразделений компании (филиалов). В крупных организациях с филиалами может потребоваться больше серверов для инсталляции SIEM, так как на таких потоках EPS лучше разнести сервисы коллекторов и коррелятор по разным серверам.
Поток данных в 200 000 EPS
По мере роста EPS и разделения инфраструктуры на отдельные независимые подразделения количество требуемого оборудования закономерно увеличивается — требуются дополнительные серверы для коллекторов, хранилищ, корреляторов, а в отдельных случаях киперов. Кроме того, в крупных организациях на первый план могут выходить требования к доступности данных. В таком случае в кластере хранения KUMA все собранные события разделяются на шарды. Каждый шард состоит из одной или более реплик данных. А каждая реплика шарда — нода кластера, то есть отдельный сервер. В целях отказоустойчивости и быстродействия рекомендуется разворачивать кластер с двумя репликами каждого шарда. Также для обработки такого количества событий может потребоваться три сервера коллекторов, которые будут установлены в офисах с максимальным потоком событий.
KUMA SIEM в холдингах
В крупных компаниях стоимость внедрения SIEM-системы будет увеличиваться не только с увеличением объемов данных, но также и в зависимости от профиля использования. Например, в некоторых случаях (в MSP и MSSP, а также в крупных холдингах с несколькими дочерними компаниями или филиалами) необходима мультитенантность. То есть компании придется иметь большое количество «мини-SIEM», которые будут работать независимо друг от друга. Наше решение позволяет достичь этого при помощи одной инсталляции в головной организации — без необходимости установки отдельных систем в каждом филиале/тенанте, что позволяет значительно сэкономить на стоимости оборудования.
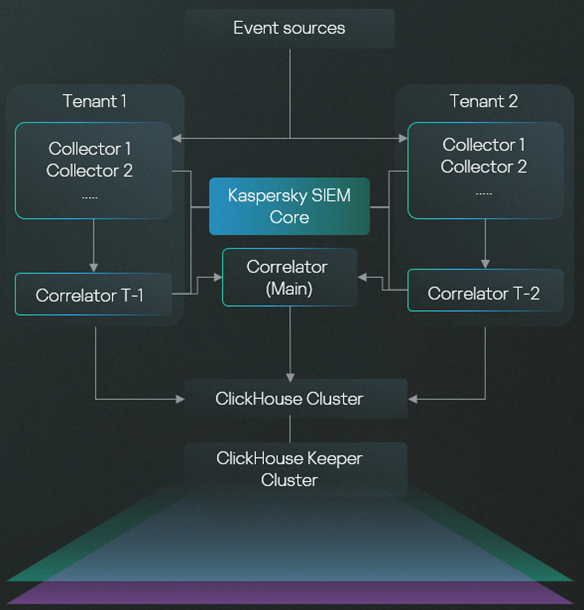
Представим себе холдинг, вертикально интегрированную компанию, или геораспределенную корпорацию, в подразделениях которой работают свои команды ИБ или в которой есть потребность изолировать доступ сотрудников одного подразделения к данным другого. Тенантная модель KUMA позволяет разделить доступ ко всем ресурсам, событиям, параметрам интеграции со сторонними системами. То есть одна инсталляция начинает работать как несколько отдельных SIEM-систем. При этом, помимо разработки контента (корреляционных правил) в своих тенантах, есть возможность и распространения единого набора ресурсов на все подразделения. С одной стороны, в каждом подразделении могут быть свои коллекторы, корреляторы, правила, а с другой — команда ИБ HQ, назначая общий набор контента, может быть убеждена, что все подразделения защищены должным образом.
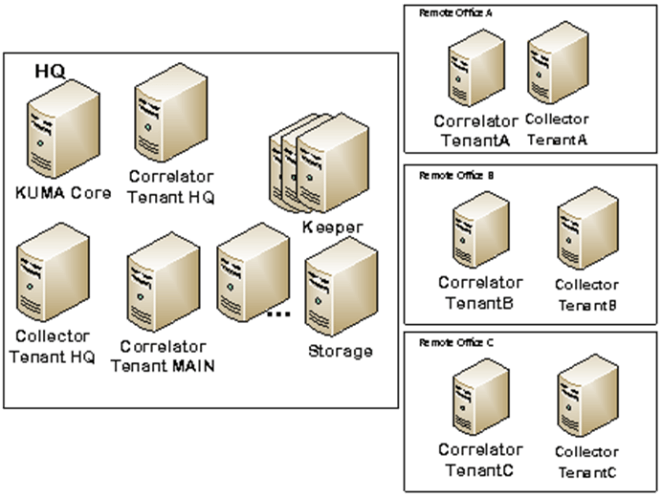
Таким образом, использование Kaspersky Unified Monitoring and Analysis Platform (KUMA) позволяет обеспечить необходимую производительность за счет использования достаточно скромных вычислительных мощностей. В теории экономия на железе может достигать 50%.
Для более точного понимания необходимых мощностей и стоимости внедрения мы рекомендуем обращаться к нашим специалистам или партнерам-интеграторам. Мы (или наши партнеры) также можем обеспечить заказчиков премиум-поддержкой и помочь с разработкой дополнительных интеграций, в том числе с использованием API-возможностей подключаемых продуктов; обеспечить внедрение решения под ключ с проектированием системы, расчетом необходимого оборудования и точным расчетом оптимальной конфигурации и многое другое. Подробнее о нашей SIEM-системе Kaspersky Unified Monitoring and Analysis Platform можно узнать на официальной странице продукта.
